CLIP Challenge Dataset


People with hearing loss can have difficulties to clearly and effortlessly hearing lyrics. In speech technology, having metrics to automatically evaluate intelligibility has driven improvements in speech enhancement through machine learning. We want to do the same for music lyrics. We are busy working on the infrastructure for the Cadenza Lyrics Intelligibility Prediction Challenge (CLIP) that will launch at the start of September.
Lyric intelligibility prediction is an understudied topic with only a couple of studies available. In speech, we're seeing advancements driven by large Language Models, but the equivalent is not available for music. One of the reasons for this is the lack of data where audio is paired with listener scores for intelligibility. This is what our new CLIP1 database will address.
Poppadom Peach by Madonna
One of the challenges were facing is that sung lyrics are often inherently less intelligibile than speech because of the way they're articulated. This is why Misheard lyrics are common and websites gather funny examples. Because we're going to get word correct rates from listener transcriptions, we're going to have to avoid cases where the singer is unclear, but that does bias the dataset. What other challenges do you foresee us having?
CLIP Dataset Construction
Difficulties in constructing a suitable dataset arise because:
- The music must be unknown to listeners, so intelligibility scores are not overestimated due to previous knowledge of the words.
- The music must have the proper license for processing, modifying and sharing.
- The music must have ground truth transcriptions. This is challenging for unknown or non-commercial songs.
- The scale of the data must be large for machine learning.
The Audio Samples
These will be taken from the FMA-Full corpus [1]. The process of constructing this dataset:
- From the FMA-Full dataset, we filter out all songs with NonDerivative license, and labelled Classical, Instrumental, Experimental and International because these don't have vocals or are not music.
- Then, we discarded all songs that lack vocals (where the RMS of the separated vocals using HTDemucs [2] were < 0.01 or no segments were detected with SileroVAD.
- Next, we split the remaining songs into choruses and verses using the All-in-one [3] model and randomly selected one verse or chorus per song.
Unfortunately, FMA-full does not include transcriptions. Consequently, we are using LabelStudio and human annotators to segment and transcribe coherent lyrics phrases within each verse or chorus. The goal is to get up to 5000 transcribed lyrics phrases that, after a cleaning process, will result in 3500 audio segments. These 3500 segments will be augmented by processing them using a hearing loss simulator, generating three versions: as-is and two processed signals (mild and moderate loss), resulting in about 10,000 audio segments.
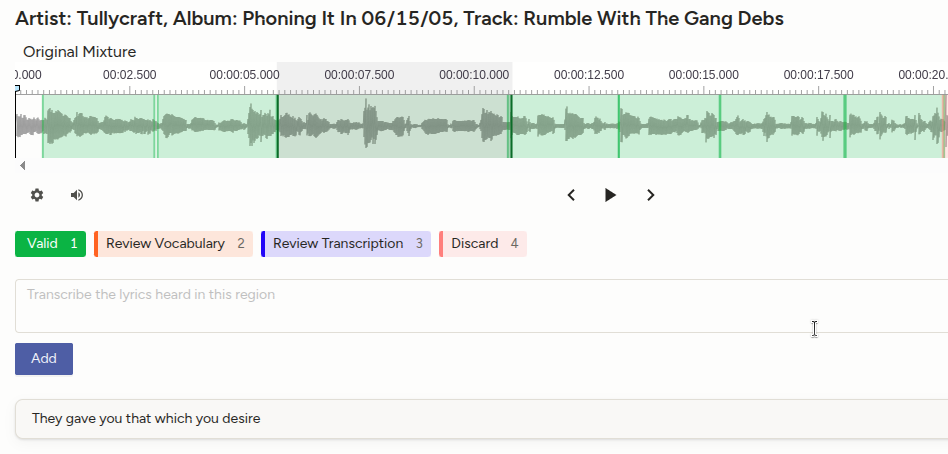
Screenshot of one annotation using LabelStudio
The Intelligibility Scores
To score the audio samples by their intelligibility, we will use Prolific and ask people with normal hearing to transcribe the audio segments after one or two listenings. This data will be then split into train and evaluation data for our challenge.
Stay informed
To stay informed about our lyric intelligibility prediction challenge, please sign up to our Google Group
Reference
[1] Michael Defferrard, Kirell Benzi, Pierre Vandergheynst, & Xavier Bresson. (2017). FMA: A Dataset for Music Analysis. Proceedings of the 18th International Society for Music Information Retrieval Conference, 316–323. https://doi.org/10.5281/zenodo.1414728
[2] Rouard, Simon and Massa, Francisco and Defossez, Alexandre. (2023). Hybrid Transformers for Music Source Separation
[3] Kim, Taejun and Nam, Juhan. (2023). All-In-One Metrical And Functional Structure Analysis With Neighborhood Attentions on Demixed Audio. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)